MLflow使用PostgresSQL

MLflow默认使用的是SQLite来存储实验数据等信息。 但是当实验数量增大,后端的查询效率会下降。
在生产环境中,我们推荐使用更为健壮的数据库,比如PostgresSQL(下文中,简写为Postgres)。
在本文中,我们就描述了,如何替换MLflow默认的SQLite为Postgres来加速后端数据的处理能力。
搭建Postgres数据库
要使用Postgre后端数据库,我们首先需要搭建一个数据库的示例。 在本文,我们简单介绍如何在本地搭建一个Postgres数据库。
为了方便显示,我们此处使用Docker来快速搭建相关的数据库。
安装Docker
在搭建之前,请安装好Docker。具体请参考Docker官网 (https://www.docker.com)进行安装。
在下文中,我们默认已经安装好了Docker环境。
创建环境变量文件.env
由于我们启动Docker的时候,希望自动加载我们预设好的密码信息。
因此,我们通过本地创建一个.env文件,其内容如下:
POSTGRES_USER=username
POSTGRES_PASSWORD=password
POSTGRES_DB=mlflow
在上面的文件中,我们设置了默认的账户、密码以及数据库名称。
启动Docker镜像
在上面的文件准备好了之后,我们就可以通过如下的命令来启动我们的Postgres镜像了。
docker run --name postgres_mlflow \
--env-file ./.env \
-v ./data:/var/lib/postgresql/data \
-e PGDATA=/var/lib/postgresql/data/db-files/ \
-p 5432:5432 \
-d postgres
在上面的命令中,我们启动了一个名为postgres_mlflow的Docker容器,使用的是postgres官方最新镜像。
同时,我们通过命令--env-file ./.env将上面创建的.env环境变量进行了加载。
另外,我们还将本地的文件夹./data映射到了容器中的/var/lib/postgresql/data数据目录。
这样,我们的数据文件,在Docker容器关闭后,仍然可以保存。
以确保数据不会随着容器的启动和关闭而导致丢失。
最后,我们将容器的5432端口,映射到了宿主机的5432端口。
这样,我们就可以访问本地的5432端口来访问我们的数据库了。
(可选)检查镜像启动情况
在镜像启动后,我们可以通过docker ps来查看镜像的启动情况。
如下面的执行结果:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e0a13ac10ec2 postgres "docker-entrypoint.s…" 5 seconds ago Up 4 seconds 0.0.0.0:5432->5432/tcp postgres_mlflow
从上面的结果中,我们可以看到,我们已经成功的启动了postgres镜像,其名称为:postgres_mlflow。
同时,我们宿主机的5432端口也映射到了容器中的5432TCP端口。
这也说明,我们的数据库在容器启动层面,是没有问题的。
如果在docker ps命令中没有看到相关的输出,可能是由于异常原因导致的。
我们可以通过docker ps -a命令来查看所有的Docker容器的启动情况,看看是否有异常发生。
我们也可以通过如下命令来检查相关的容器失败原因:
docker logs <CONTAINER_ID>:此命令可以帮助我们查看到失败容器的日志信息。docker inspect <CONTAINER_ID>:此命令可以帮助我们查看相关容器的配置信息等。
(可选)连接测试Postgres数据库
为了验证我们的数据库是否搭建完毕,我们可以启动 Adminer Docker镜像,来测试我们的数据库服务。 我们通过下面的命令,来启动相关的服务:
docker run --link postgres_mlflow:db -p 8080:8080 -d adminer
上述命令中的--link postgres_mlflow:db的意思是,
我们希望将上面postgres_mlflow命名的容器以db的别名,
被我们新创建的adminer镜像容器来进行访问。
启动成功后,我们可以通过浏览器打开网址: http://localhost:8080来查看我们的数据库。
我们在登陆界面,我们选择PostgreSQL,并输入相关的登陆信息,如:
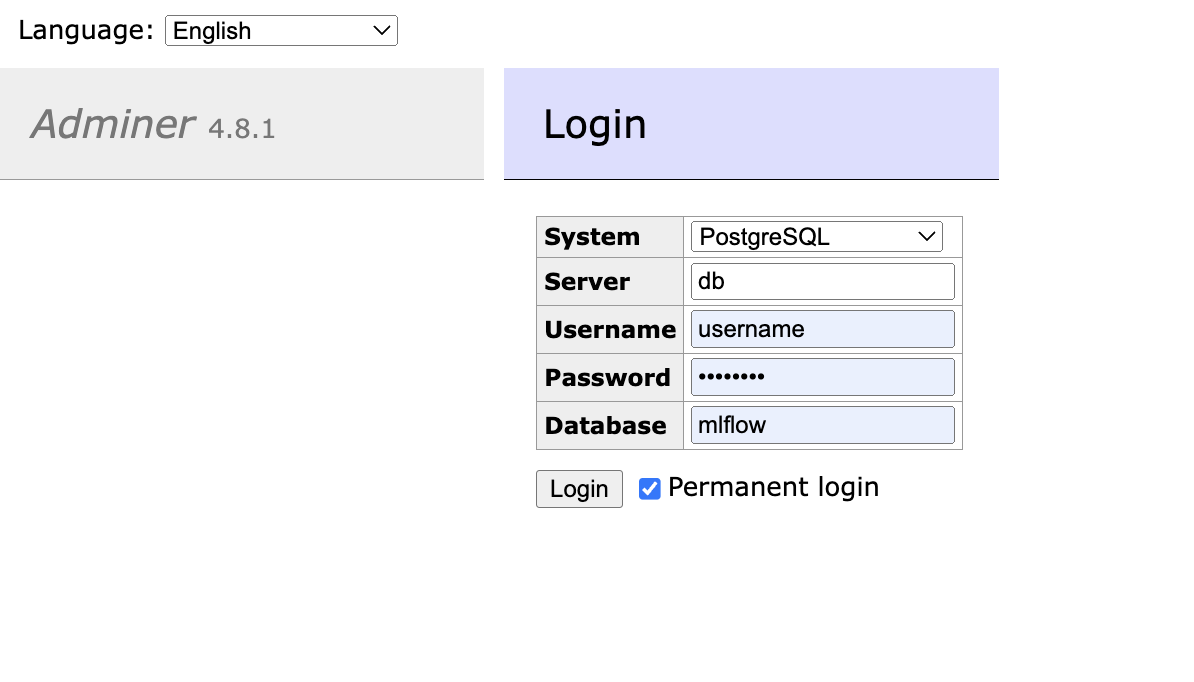
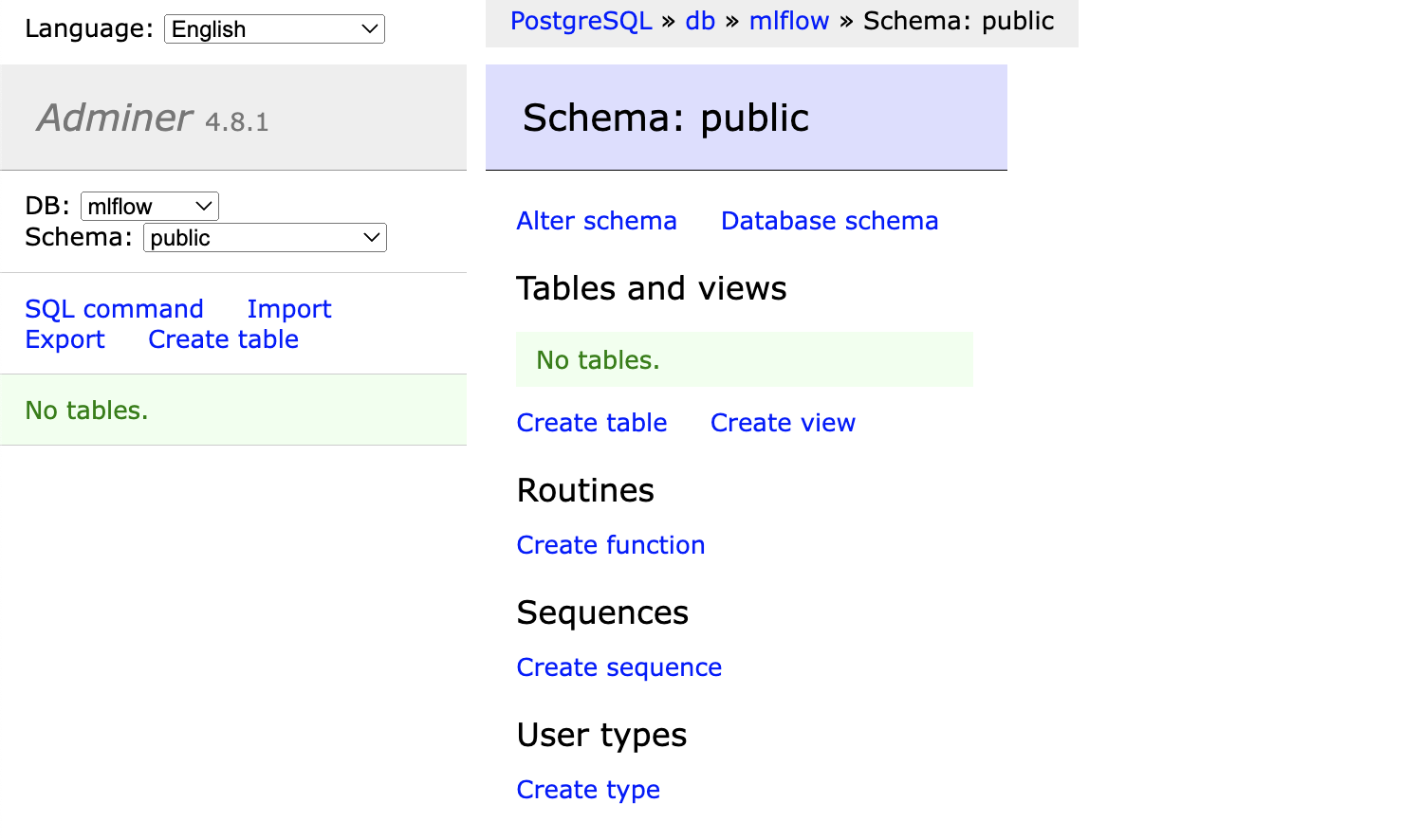
点击Login登陆按钮后,我们可以顺利看到我们的系统信息,如:
小结
以上,我们通过Docker容器的方式,顺利的搭建来本地的Postgres数据库。
接下来,我们就可以修改MLflow的后台服务器地址,来使用我们新搭建的Postgres数据库服务了。
MLflow使用新的数据库
MLflow Server在启动的时候,有一个--backend-store-uri参数。
该参数默认使用本地一个名为./mlruns的文件夹,来存储所有的实验数据。
我们通过提供一个SQLAlchemy可接受的数据库连接字符串来让MLflow服务器连接我们的Postgres数据库。
将.env文件内容设置为环境变量
为了增加安全性,我们希望通过将.env文件内容暴露到环境变量中的方式,
让MLflow可以使用相关的数据库密码信息。
使用如下命令,我们可以将.env文件信息暴露:
export $(cat .env | xargs)
我们可以通过如下命令测试效果:
echo $POSTGRES_USER
其输出应为:
username
使用新的数据库
当我们的环境变量中,已经有我们需要的账号密码信息后, 我们可以通过命令连接我们的数据库:
mlflow server \
--host 0.0.0.0 \
--port 8081 \
--backend-store-uri postgresql://$POSTGRES_USER:$POSTGRES_PASSWORD@localhost:5432/mlflow
其中--backend-store-uri的参数的含义为:
使用账号($POSTGRES_USER)以及密码($POSTGRES_PASSWORD),
连接到本地(localhost)的5432端口的mlflow数据库。
在MLflow启动成功后,通过浏览器打开:http://localhost:8081, 我们可以看到一个崭新的MLflow实例。 如下图所示:
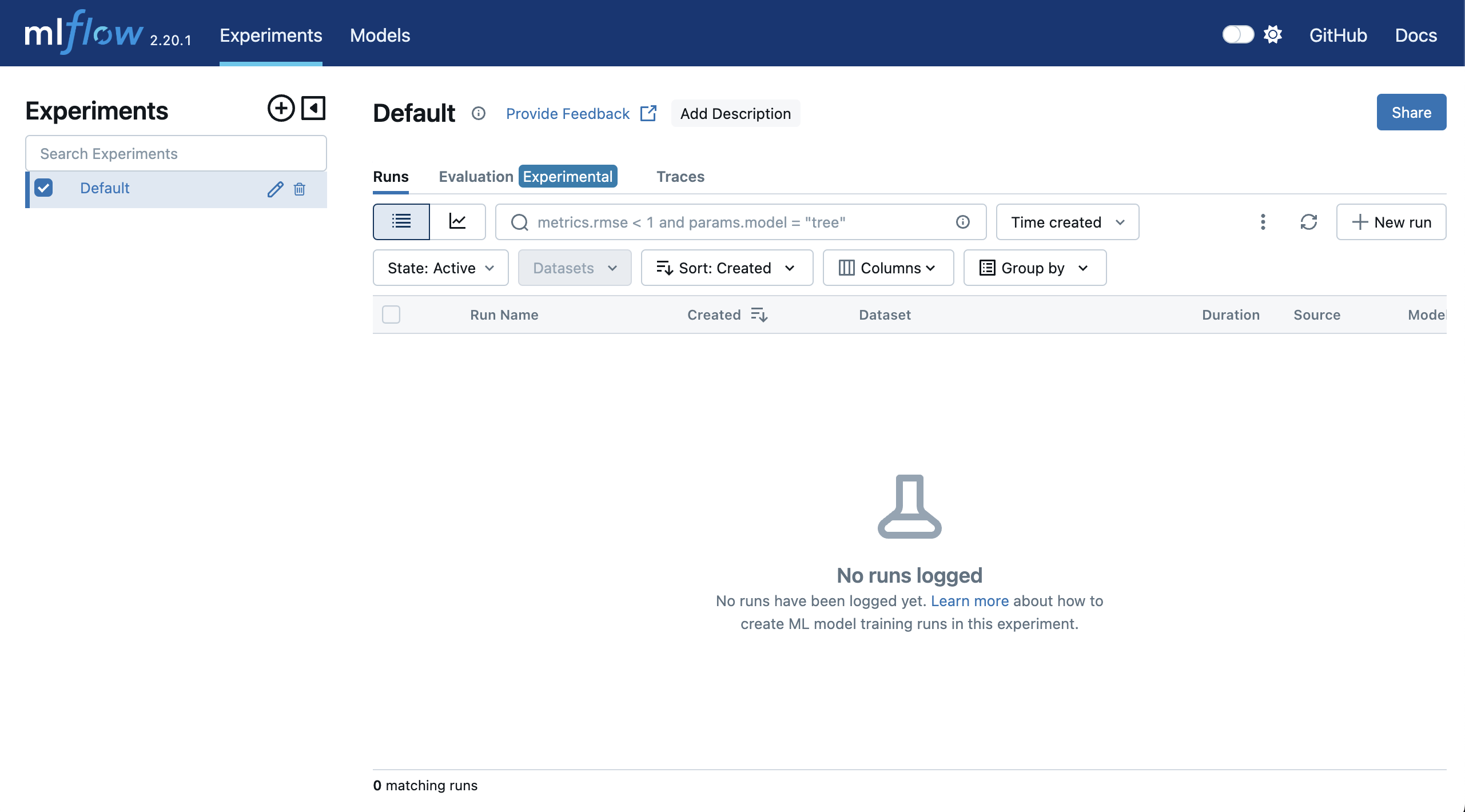
如果之前有启动过MLflow的话,可以看到之前的记录都已经消失了。 这是因为我们启动了一个新的数据库,之前的记录在另外的地方。
(可选)使用Docker运行MLflow
docker run -p 8090:5000 \
--link postgres_mlflow:db \
--env-file .env \
-v ./artifacts=/mlflow/artifacts \
ghcr.io/mlflow/mlflow \
bash -c "python3 -m pip install pip --upgrade && python3 -m pip install psycopg2-binary && mlflow server"
使用上面的代码,我们可以使用Docker来运行我们的MLFlow服务。
在上面的代码中,我们需要合理的设置.env文件的内容,其可包括如下内容:
POSTGRES_USER=****
POSTGRES_PASSWORD=****
POSTGRES_DB=mlflow
MLFLOW_BACKEND_STORE_URI=postgresql://****:****@db:5432/mlflow
MLFLOW_HOST=0.0.0.0
MLFLOW_PORT=5000
(可选)检查数据库
在MLflow启动后,我们可以再次打开之前创建的Adminer工具,来查看数据库是否运行正常。
我们选择mlflow数据库后,可以看到系统自动创建的表信息,如下图所示:
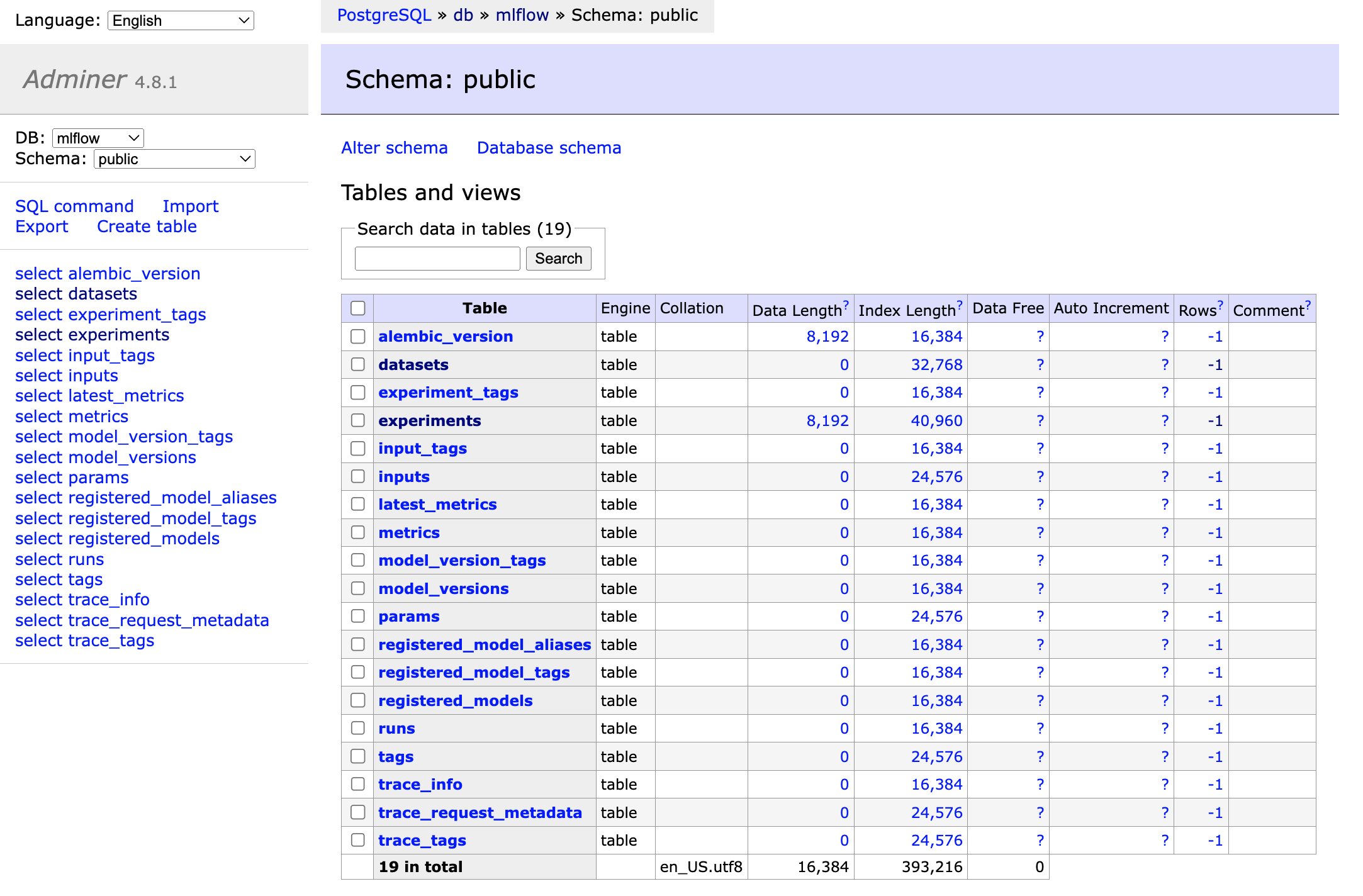
这也说明,我们后续的MLflow数据会存储到相关的数据库表中。
如果我们要在后续进行数据库操作,可以登陆到数据库的后台,进行相关的操作。
总结
在本文中,我们通过Docker搭建了一个Postgres的数据库服务。 并调整了MLflow的启动方式,让其连接我们新的数据库来存储实验数据,确保可以长期的存储实验结果。
需要注意的是,我们在本文中的方法仅为演示目的。 如果是真正的生产环境,还需要搭建生产环境标准的数据库以及MLflow实例。